


NVIDIA ने एक ऐसा AI ब्रेकथ्रू पेश किया है जिसने टेक इंडस्ट्री में हलचल मचा दी है। कंपनी ने अपने रिसर्च पेपर (21 अगस्त 2025, arXiv) में Jet-Nemotron नाम की नई तकनीक का खुलासा किया है, जो बड़े भाषा मॉडल्स (LLMs) की स्पीड को 53x तक बढ़ा सकती है। इसका मतलब है कि AI inference की लागत 98% तक कम हो सकती है, और सबसे खास बात यह है कि इसके लिए किसी मॉडल को दोबारा ट्रेन करने की ज़रूरत नहीं है।
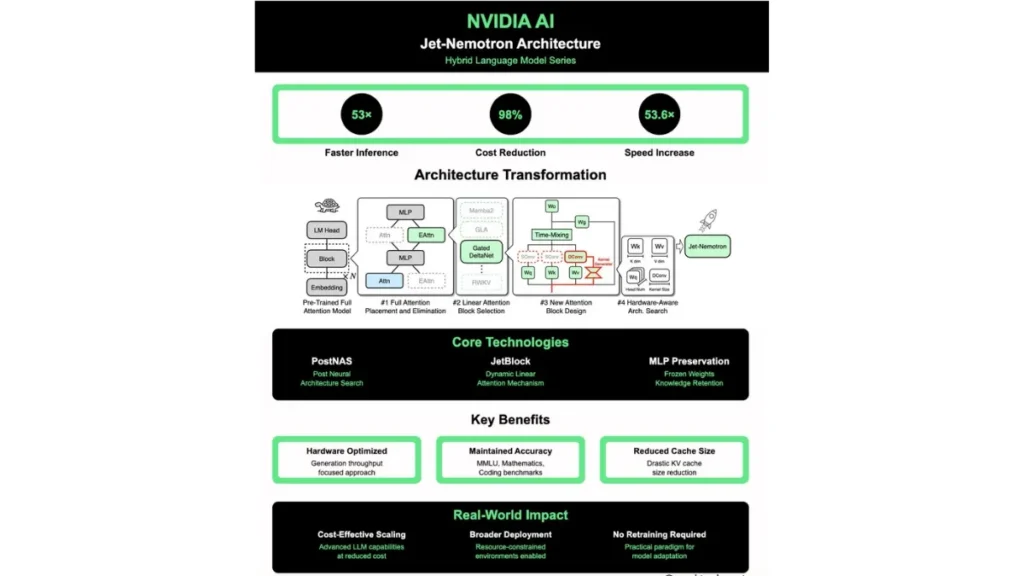
इस तकनीक में NVIDIA ने Post Neural Architecture Search (PostNAS) का इस्तेमाल किया है। पारंपरिक full-attention लेयर्स को हटाकर, उनकी जगह JetBlock designs लगाए गए हैं, जो कहीं ज्यादा तेज़ और कुशल साबित हो रहे हैं। यह तरीका मौजूदा मॉडल्स पर ही लागू हो सकता है, यानी जो डेवलपर्स पहले से LLMs का इस्तेमाल कर रहे हैं, वे बिना अतिरिक्त ट्रेनिंग खर्च के तुरंत लाभ उठा पाएंगे।
Jet-Nemotron का फायदा सिर्फ क्लाउड डेटा सेंटर्स तक सीमित नहीं है। NVIDIA ने दिखाया कि यह तकनीक edge devices जैसे Jetson Orin (जहां 8.84x स्पीडअप मिला) और RTX 3090 GPU (6.5x स्पीडअप) पर भी शानदार काम करती है। इसका मतलब है कि हाई-परफॉर्मेंस AI सिर्फ महंगे सर्वर्स तक सीमित नहीं रहेगा, बल्कि लोकल मशीनों और छोटे हार्डवेयर पर भी चल सकेगा।
यह शोध NVIDIA H100 GPU की 3 TB/s मेमोरी बैंडविड्थ का भी इस्तेमाल करता है, जिससे CPU-आधारित सिस्टम्स के मुकाबले 40x तक बेहतर प्रदर्शन मिलता है। साथ ही, नया KV cache डिज़ाइन (154MB) throughput को और मजबूत बनाता है, जिससे लोकल डिप्लॉयमेंट पहले से कहीं ज्यादा आसान हो गया है।
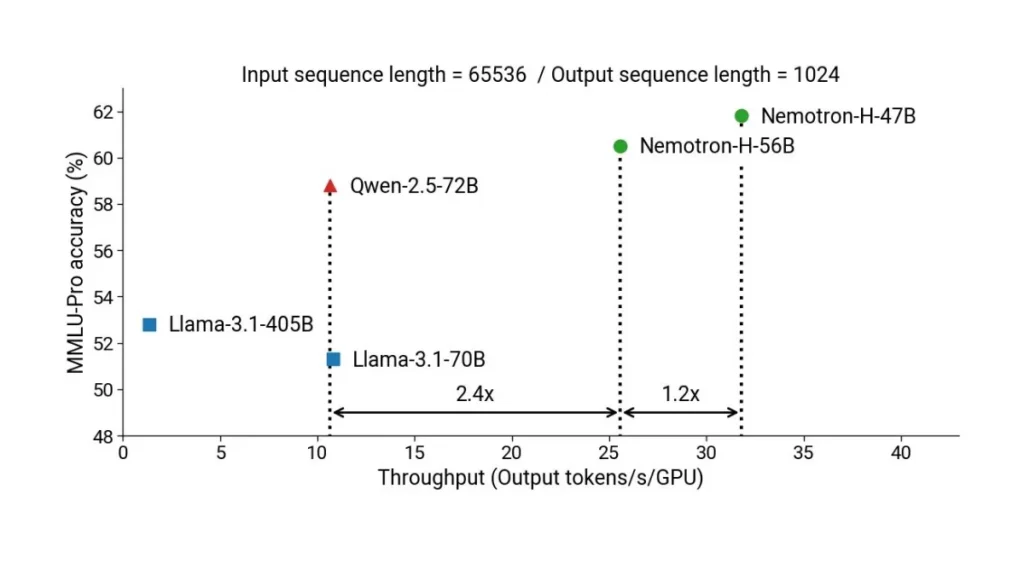
AI इंडस्ट्री में यह कदम एक बड़ा मोड़ साबित हो सकता है। अभी तक यह धारणा थी कि बड़े भाषा मॉडल्स को चलाने के लिए महंगे GPU क्लस्टर्स और डेटा सेंटर की ज़रूरत होती है। लेकिन Jet-Nemotron यह मिथ तोड़ रहा है और यह दिखा रहा है कि कम लागत और तेज़ स्पीड के साथ AI को edge devices और छोटे स्टार्टअप्स भी अपना सकते हैं।
NVIDIA का यह इनोवेशन सीधे तौर पर उस भविष्य की ओर इशारा करता है जहां AI सभी के लिए अधिक सुलभ और सस्ता होगा। इससे स्टार्टअप्स, रिसर्चर्स और इंडी डेवलपर्स को बड़ा फायदा मिलेगा क्योंकि अब उन्हें महंगे इन्फ्रास्ट्रक्चर की बाधाओं से जूझना नहीं पड़ेगा।




